
Praktyczny przewodnik rozróżniania projektów, incydentów i zgłoszeń serwisowych w IT. Naucz się poprawnie klasyfikować zgłoszenia zgodnie z ITIL i optymalizuj pracę działu IT.

Od pierwszej rozmowy do pełnego partnerstwa: Jak przebiega proces przyjmowania nowych klientów w 99NET
Przejście na outsourcing IT to strategiczna decyzja, która może przynieść Twojej firmie wymierne korzyści: redukcję kosztów, dostęp do eksperckiej wiedzy i zwiększenie bezpieczeństwa IT. Jednak sukces tej transformacji zależy od właściwie przeprowadzonego procesu onboardingu.

Obsługa klienta w Service Desk: Niezbędne umiejętności w erze cyfrowej transformacji
Czy wiesz, że 68% klientów rezygnuje z usług firmy z powodu złej obsługi technicznej? W erze cyfrowej transformacji, Service Desk nie jest już tylko „help deskiem”, ale strategicznym centrum doświadczeń klienta. Poznaj kluczowe umiejętności, które decydują o sukcesie w obsłudze IT.

Major Incident Management: Strategiczne zarządzanie krytycznymi awariami


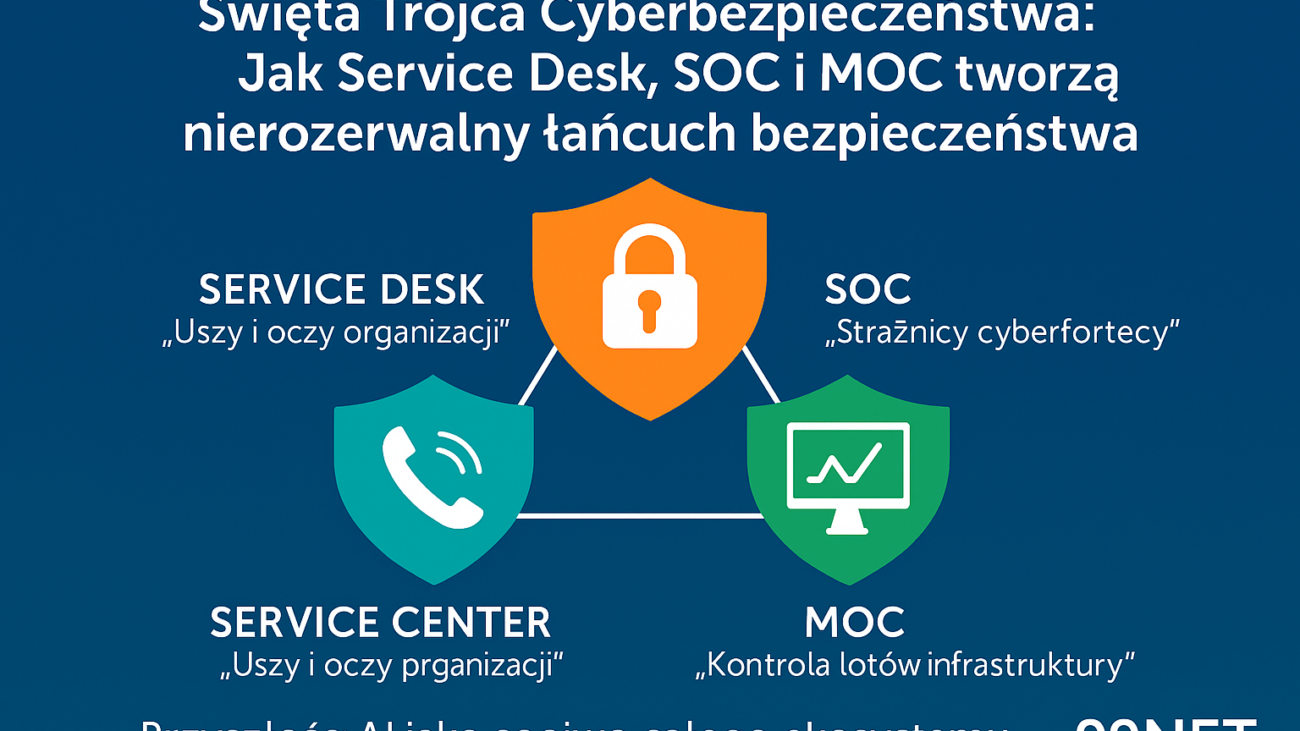
Święta Trójca Cyberbezpieczeństwa: Jak Service Desk, SOC i MOC tworzą nierozerwalny łańcuch bezpieczeństwa
Service Desk, SOC i MOC: Synergia w Zarządzaniu IT | Kompleksowy Przewodnik. Dowiedz się, jak zintegrować te trzy centra operacyjne, aby zredukować czas reakcji na incydenty o 65% i zwiększyć bezpieczeństwo. Praktyczne scenariusze i korzyści.

Model Wielowarstwowego Service Desk: Charakterystyka Linii Biznesowych

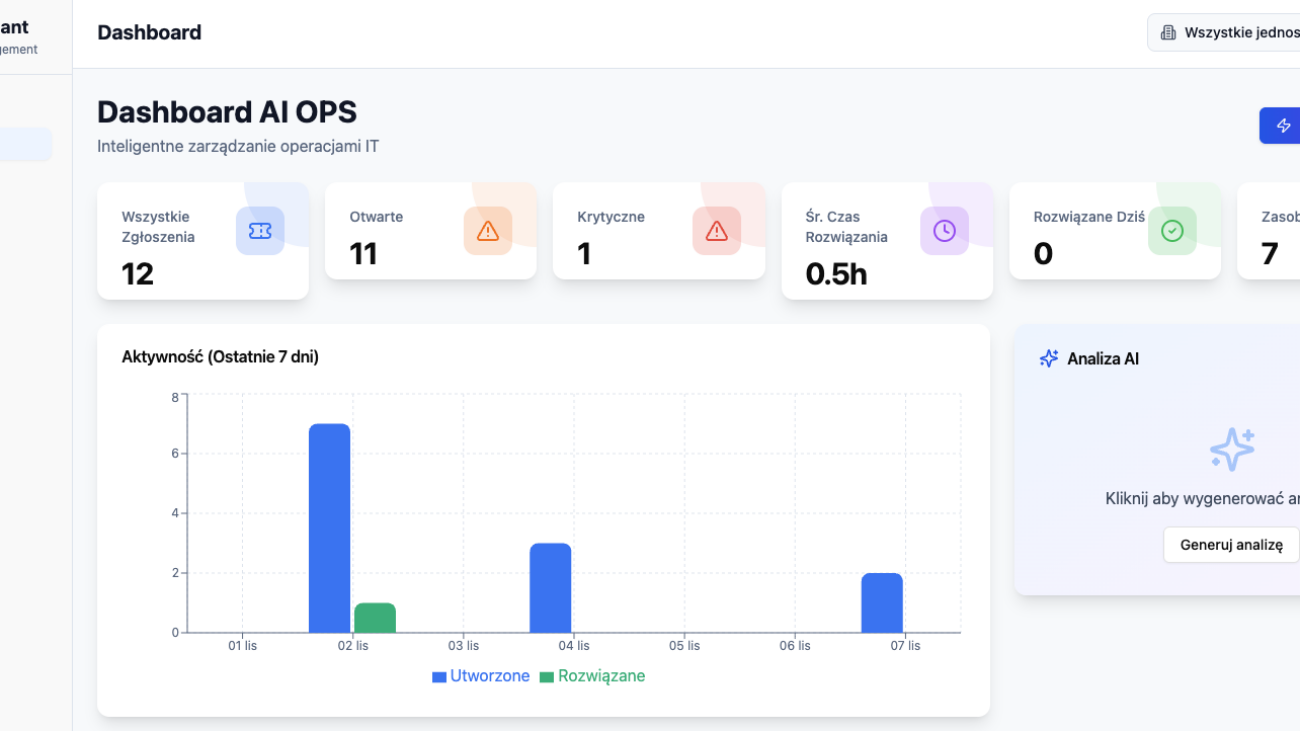
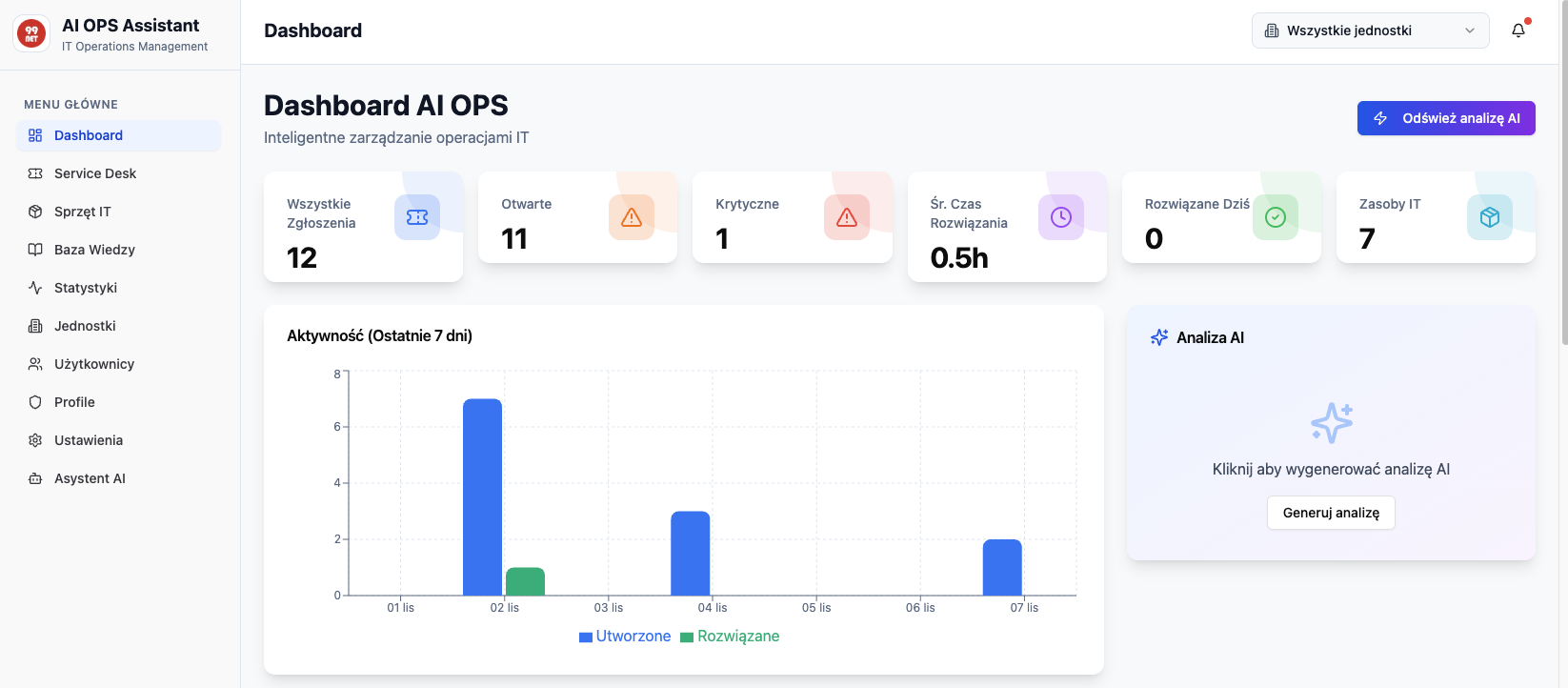
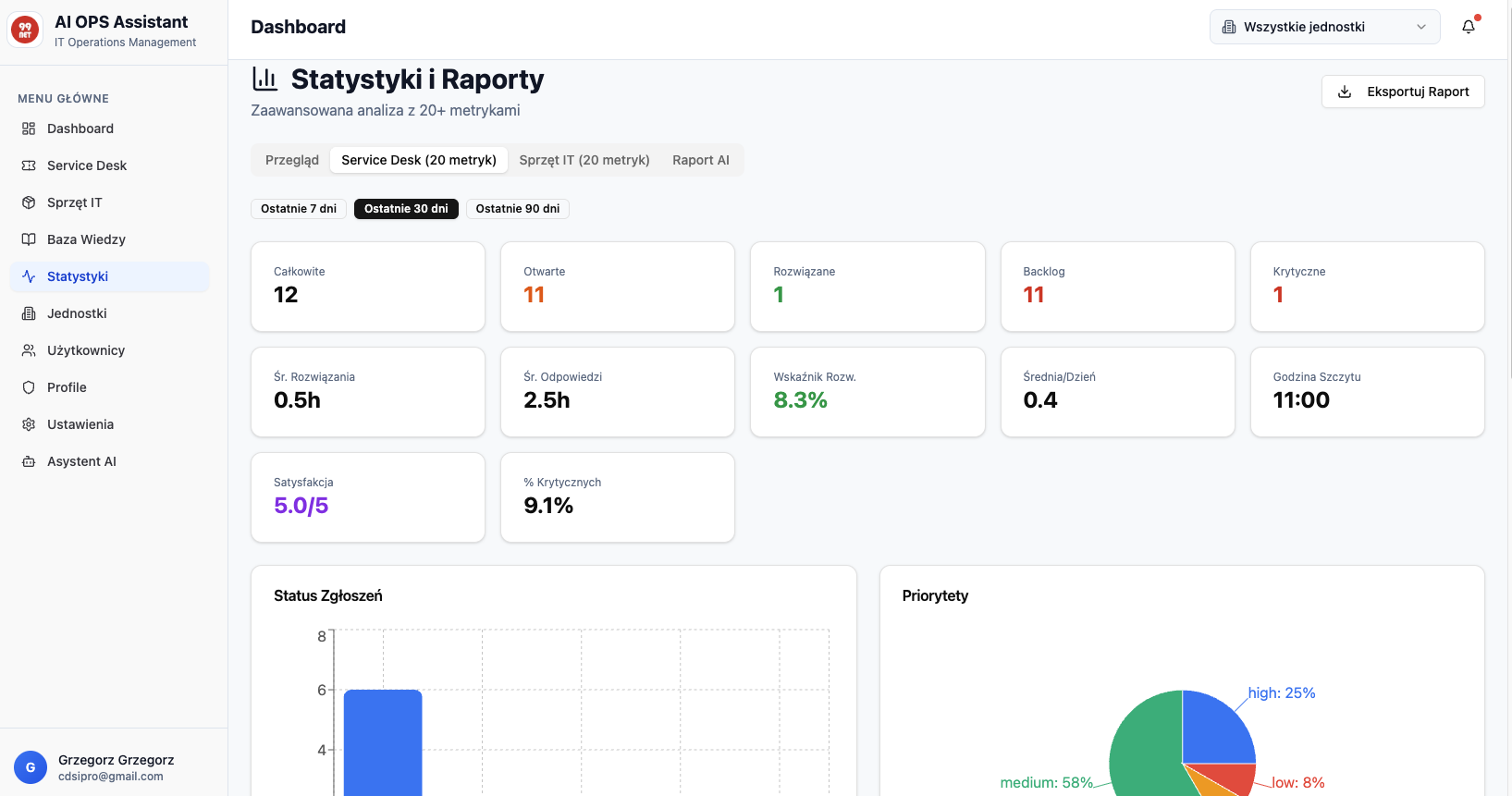
Helpdesk, Service Desk a IT Zarządcze: Ewolucja Wsparcia IT od Reakcji do Strategii
Czy Twój dział IT wciąż tylko „gaszi pożary”, a jego rolę postrzega się jako centrum kosztów? Poznaj trzy poziomy dojrzałości wsparcia technologicznego: od reaktywnego Helpdesku, przez zorientowany na usługi Service Desk, aż po strategiczne IT Zarządcze. Dowiedz się, jak przekształcić IT z kosztu w siłę napędową biznesu i strategicznego partnera w osiąganiu celów organizacji.
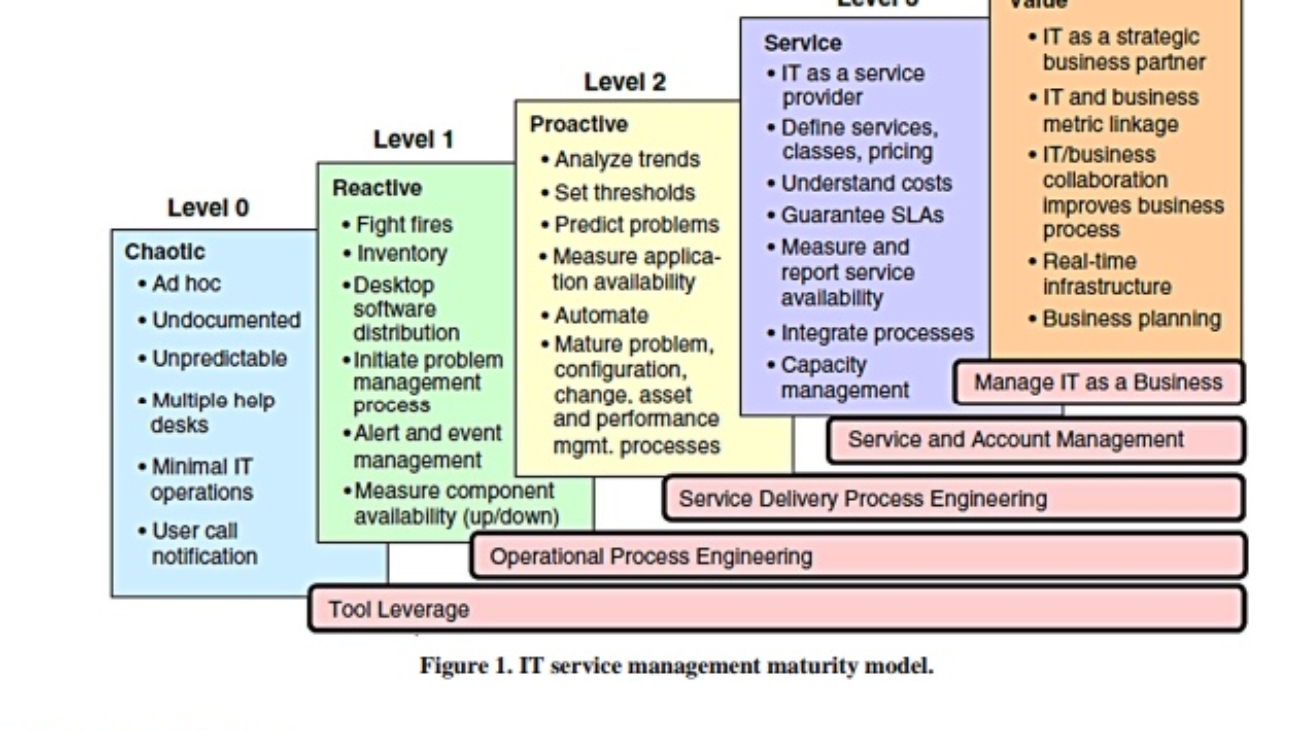
Budowanie dojrzałości IT: Kluczowa rola Service Desk w oparciu o ITIL i ITSM
Poznaj kluczowe elementy budowania dojrzałości IT w oparciu o ITIL i ITSM. Dowiedz się, jak nowoczesny Service Desk wpływa na efektywność zarządzania usługami IT, poprawę satysfakcji klientów i redukcję kosztów. Sprawdź case study i praktyczne wskazówki.

Matryca RACI: Klucz do efektywnego zarządzania rolami i odpowiedzialnością w IT
Zarządzanie Projektami IT Matryca RACI w IT:
Matryca RACI w IT:
Klarowność Ról, Efektywna Współpraca
W dynamicznych środowiskach IT, gdzie różne zespoły współpracują przy projektach, łatwo o niejasności w zakresie obowiązków. Matryca RACI (Responsible, Accountable, Consulted, Informed) eliminuje te niejasności, zwiększając przejrzystość i usprawniając komunikację.
-70% Nieporozumień w zespole
+40% Efektywności projektu
100% Klarowności odpowiedzialności
Czym jest Matryca RACI?
RACI to akronim definiujący cztery kluczowe role przypisywane do każdego zadania lub procesu. To mapa nawigacyjna dla odpowiedzialności, która pozwala zespołom skupić się na tworzeniu wartości zamiast na rozwiązywaniu nieporozumień.
R
Responsible
Odpowiedzialny
Wykonawcy. Osoba lub zespół, który faktycznie wykonuje pracę. Może być kilka osób oznaczonych jako "R" dla jednego zadania.
A
Accountable
Właściciel
Właściciel zadania. Osoba, która ponosi ostateczną odpowiedzialność. Tylko ona ma uprawnienia do zatwierdzenia wyniku.
ZASADA: Jedno "A" na zadanie
C
Consulted
Konsultowany
Doradcy. Osoby, których wiedza jest potrzebna przed podjęciem działania. Komunikacja z nimi jest dwukierunkowa.
I
Informed
Informowany
Interesariusze. Osoby, które muszą być informowane o postępach, ale nie mają bezpośredniego wpływu na wykonanie.
Dlaczego RACI to "must-have" w IT?
Wdrożenie matrycy RACI przynosi namacalne korzyści dla organizacji IT:
01
Likwiduje "szarą strefę" odpowiedzialności
Każdy członek zespołu wie, co do niego należy i czego może oczekiwać od innych. Eliminuje sytuacje, w których zadania "wiszą w powietrzu".
02
Przyspiesza podejmowanie decyzji
Wiadomo, kto („A”) ma prawo podjąć decyzję, a kogo („C”) należy wcześniej zapytać. Skraca to czas oczekiwania na akceptację.
03
Poprawia jakość komunikacji
Eliminuje zbędne spotkania i maile, kierując informacje do właściwych osób we właściwym czasie. Redukuje szum komunikacyjny.
04
Zwiększa efektywność zespołu
Zespoły zyskują autonomię w działaniu, co zwiększa ich zaangażowanie i odpowiedzialność za wyniki projektu.
Przykłady zastosowania w IT
Wdrożenie aktualizacji bezpieczeństwa
Security Patch Management w środowisku korporacyjnym:
| Zadanie | Admin Systemowy | Kierownik IT | Spec. Bezpieczeństwa | Użytkownicy |
|---|---|---|---|---|
| Ocena krytyczności łatki | C | A | R | I |
| Testowanie w środowisku testowym | R | A | C | - |
| Zaplanowanie okna serwisowego | R | A | C | I |
| Wdrożenie na produkcji | R | A | - | I |
| Weryfikacja poprawności | R | A | C | - |
Rozwój funkcjonalności w DevOps
Proces CI/CD dla nowej funkcjonalności aplikacji:
| Etap procesu | Developer | DevOps Engineer | QA Tester | Product Owner | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Implementacja funkcji | R | - | C | I | |||||||||||||||||||||
| Utworzenie pipeline'u CI/CD | C | R | - | I | |||||||||||||||||||||
| Testy automatyczne | C | R | A | I | |||||||||||||||||||||
| Wdrożenie na staging | - | R | A |  Podejście do Zarządzania IT: Reaktywność, Prewencja, Predyktywność i PreskrypcyjnośćW dynamicznie zmieniającym się świecie technologii informatycznych (IT)skuteczne zarządzanie infrastrukturą IT i procesami organizacyjnymi wymaga przyjęcia odpowiedniego podejścia. Współczesne firmy coraz częściej przechodzą od modelu reaktywnego do bardziej zaawansowanych strategii, takich jak prewencja, predyktywność i preskrypcyjność. Każde z tych podejść ma swoje zalety i zastosowanie, które można dostosować do specyfiki danej organizacji.  Reaktywność: Pierwszy krok w zarządzaniu ITReaktywność to podejście polegające na reagowaniu na problemy dopiero w momencie, gdy już się pojawią. W modelu reaktywnym administratorzy IT podejmują działania naprawcze w odpowiedzi na zgłoszenia użytkowników lub wykryte awarie. Zalety reaktywności:
Wady reaktywności:
Przykład w praktyce:Firma korzystająca z reaktywnego podejścia czeka na zgłoszenia użytkowników dotyczące problemów, takich jak niedostępność serwera czy awarie sprzętu, zanim podejmie działania. Prewencja: Zarządzanie przez zapobieganiePrewencja to proaktywne podejście, które polega na identyfikowaniu i eliminowaniu potencjalnych problemów, zanim one wystąpią. Organizacje wdrażają procesy i narzędzia, które minimalizują ryzyko awarii i zakłóceń. Zalety prewencji:
Wady prewencji:
Przykład w praktyce:Firma korzystająca z prewencji wdraża system monitorowania serwerów, który identyfikuje zużycie zasobów i ostrzega administratorów przed potencjalnym przeciążeniem. Predyktywność: Prognozowanie przyszłości na podstawie danychPredyktywność to podejście wykorzystujące analizę danych i modele predykcyjne do prognozowania przyszłych zdarzeń. Dzięki zastosowaniu sztucznej inteligencji i uczenia maszynowego możliwe jest przewidywanie awarii, trendów w obciążeniu systemów czy zapotrzebowania na zasoby. Zalety predyktywności:
Wady predyktywności:
Przykład w praktyce:Firma wykorzystująca predyktywność analizuje dane historyczne z systemów IT, aby przewidzieć moment, w którym dyski twarde w serwerach osiągną limit swojej wydajności, i planuje ich wymianę z wyprzedzeniem. Preskrypcyjność: Automatyzacja decyzji i działańPreskrypcyjność to najbardziej zaawansowane podejście, które nie tylko przewiduje problemy, ale również sugeruje lub automatycznie wdraża działania naprawcze. Opiera się na zaawansowanej analityce i mechanizmach sztucznej inteligencji, aby podejmować decyzje w czasie rzeczywistym. Zalety preskrypcyjności:
Wady preskrypcyjności:
Przykład w praktyce:Firma wdraża system, który automatycznie przełącza obciążenie na zapasowe serwery w przypadku awarii głównego systemu, jednocześnie wysyłając zgłoszenie do działu IT i generując raport o problemie. Porównanie podejść
Jak wdrożyć te podejścia w organizacji?
PodsumowanieZarządzanie IT wymaga dynamicznego podejścia, które pozwala na dostosowanie strategii do specyfiki organizacji. Przejście od reaktywności do prewencji, predyktywności i preskrypcyjności może znacząco poprawić wydajność i niezawodność systemów IT. Wybór odpowiedniego modelu zależy od poziomu zaawansowania organizacji, dostępnych zasobów i celów biznesowych. Dzięki nowoczesnym technologiom i narzędziom każda firma może skutecznie wdrażać te podejścia, zwiększając swoją konkurencyjność i stabilność operacyjną. Twoja organizacja zmaga się z wydajnością a zgłoszenia serwisowe to niekończąca się walka. Napisz, podzielimy się z Tobą doświadczeniem. |