Prywatny ChatGPT na Twoim Komputerze: Ollama
W dobie rosnącej popularności modeli językowych takich jak ChatGPT, coraz więcej użytkowników poszukuje prywatności i kontroli nad swoimi danymi. Ollama to narzędzie, które pozwala na uruchomienie prywatnego chatbota AI bezpośrednio na Twoim komputerze, oferując pełną niezależność od zewnętrznych serwerów.
Co to jest Ollama?
Ollama to platforma, która umożliwia lokalne wdrażanie zaawansowanych modeli językowych. Dzięki temu Twoje rozmowy i dane są przechowywane wyłącznie na Twoim urządzeniu. To idealne rozwiązanie dla osób i firm, które cenią sobie prywatność i bezpieczeństwo informacji.
Jak Zainstalować Ollama na Windows: Przewodnik Krok po Kroku
Lokalne modele językowe stają się coraz bardziej popularne, szczególnie wśród osób, które chcą pracować z AI bez potrzeby połączenia z Internetem. Ollama to jedno z takich narzędzi, które pozwala uruchamiać modele językowe (LLM) lokalnie.
W tym artykule dowiesz się, jak zainstalować Ollama na systemie Windows oraz jak skonfigurować interfejs graficzny za pomocą Open WebUI.
Dlaczego Warto Korzystać z Ollama?
Ollama umożliwia uruchamianie zaawansowanych modeli językowych na Twoim komputerze bez potrzeby przesyłania danych do chmury. Dzięki temu:
- Możesz pracować offline.
- Zachowujesz pełną kontrolę nad swoimi danymi.
- Masz możliwość korzystania z szerokiego wachlarza modeli językowych.
Wymagania Systemowe
Przed instalacją upewnij się, że Twój komputer spełnia następujące wymagania:
- System operacyjny: Windows 10 lub Linux Ubuntu 22.04 (nie wyższy).
- Procesor: Obsługa instrukcji AVX2 (większość nowoczesnych procesorów).
- Karta Graficzna: Im mocniejsza tym lepiej dla szybkości działania Ollamy jak RTX 4090
- Pamięć RAM: Zalecane 16 GB lub więcej.
- Dysk twardy: Minimum 10 GB wolnego miejsca.
Instalacja Ollama
1. Pobierz WSL dla Windows
Uruchom poprzez komendę PoweShell wsl i wykonaj instalację.
1. Pobierz Ollama
Wejdź na oficjalną stronę Ollama i pobierz wersję instalacyjną dla systemu Linux.
2. Skonfiguruj Serwer
Uruchom instalator (dla Linux)
Otwórz Wiersz Poleceń (PowerShell) jako administrator i uruchom serwer Linux poprzez komendę wsl
Pobierz i zainstaluj Ollama.
curl -fsSL https://ollama.com/install.sh | sh Pobierz jeden (lub wiele) z najpopularniejszych modeli (llama3 lub mistral)
ollama pull llama3Uruchom model poprzez
ollama run llama3
Serwer działa na domyślnym porcie localhost:8000
Różnice pomiędzy Llama a Open AI
| Kategoria | Llama | GPT (OpenAI) |
|---|---|---|
| Dostępność | Open-source; dostępny dla społeczności badawczej i komercyjnej. | Zamknięty kod; dostęp przez API i interfejsy użytkownika. |
| Rozmiar modelu | Llama 3: 8B, 70B, 405B parametrów. Reuters | GPT-4: około 1,76T parametrów. CodeSmith |
| Okno kontekstowe | Llama 3: do 4,096 tokenów. CodeSmith | GPT-4: do 32,768 tokenów. CodeSmith |
| Modalności | Tekst; planowane dodanie obsługi obrazów, wideo i mowy. Reuters | Tekst i obrazy (wejście); tekst (wyjście). CodeSmith |
| Licencjonowanie | Głównie darmowy dla deweloperów; ograniczenia dla firm z ponad 700 mln aktywnych użytkowników. CodeSmith | Komercyjny; opłaty za dostęp do API. |
| Wydajność | Llama 3.1 z 405B parametrów osiąga wyniki zbliżone do GPT-4 w testach matematycznych i językowych. Reuters | GPT-4 przewyższa Llama 2 w większości zadań; szczegóły dotyczące GPT-4 nie są publicznie dostępne. Incantata |
Źródła:
- Meta Llama 2 vs. OpenAI GPT-4: A Comparative Analysis
- Meta unveils biggest Llama 3 AI model, touting language and math gains
- Host-your-own Llama 2 vs OpenAI GPT-4
Przyjazny Interfejs Użytkownika
Aby zainstalować Open WebUI, przyjazny interfejs użytkownika do obsługi swoich modeli językowych (LLM), możesz skorzystać z pomocy Linuxa (także WSL dla Windows)
Wymagany Linux lub dla Windows (WSL). Pobierz ze sklepu Microsoft.
Testowaliśmy Ubuntu.
1. Instalacja za pomocą Pythona i pip
Krok 1:
Upewnij się, że masz zainstalowaną wersję Pythona 3.11.x oraz moduł Pip, ponieważ nowsze wersje mogą być niekompatybilne z Open WebUI.
Krok 2:
Dodaj odpowienią wersję Python 3.11 oraz Pip
sudo apt-get install git gcc make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev
curl https://pyenv.run | bash
export PATH="/home/$(whoami)/.pyenv/bin:$PATH"export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"Zrestartuj basha.
source ~/.bashrcDodaj braki do pynv
sudo apt-get install lzma
sudo apt-get install liblzma-devZainstaluj Python 3.11
pyenv install 3.11
pyenv global 3.11
pip install pip --upgrade
pyenv local 3.11Krok 3:
Otwórz terminal i zainstaluj Open WebUI poleceniem.
pip install open-webui
Krok 4:
Po zakończeniu instalacji uruchom serwer Open WebUI:
open-webui serve
Krok 5:
Otwórz przeglądarkę i przejdź do http://localhost:8080, aby uzyskać dostęp do interfejsu Open WebUI.
Uwaga: Ta metoda jest zalecana dla użytkowników preferujących bezpośrednią instalację bez użycia kontenerów Docker. Wymagany Linux lub WSL (Ubuntu) dla użytkowników Windows.
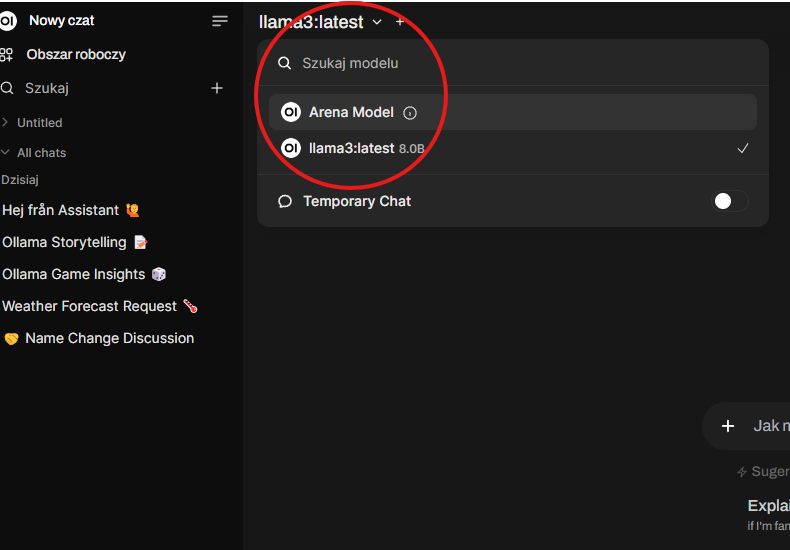
Po zalogowaniu, wybierz z menu właściwy model:
Karta graficzna a wydajność odczytu
Mocna karta graficzna (GPU) jest kluczowa dla serwera Ollama z kilku powodów, szczególnie w kontekście jego wykorzystania do przetwarzania dużych ilości danych, uczenia maszynowego i innych zadań związanych z zaawansowaną analizą:
1. Przyspieszenie obliczeń równoległych
- GPU są zoptymalizowane pod kątem obliczeń równoległych, co czyni je znacznie bardziej efektywnymi w przetwarzaniu dużych zbiorów danych w krótkim czasie.
- Serwer Ollama, który obsługuje modele językowe i operacje na dużych zbiorach danych, może dzięki GPU przyspieszyć:
- Obliczenia matematyczne.
- Operacje na macierzach (kluczowe w sztucznej inteligencji i przetwarzaniu języka naturalnego).
2. Obsługa zaawansowanych modeli językowych (LLMs)
- Modele językowe, takie jak GPT, działają na dużych zestawach danych i wymagają znacznych zasobów obliczeniowych. Mocna karta graficzna:
- Umożliwia efektywną obsługę dużych modeli, takich jak LLM (Large Language Models).
- Przyspiesza trening modeli i pozwala na bardziej wydajne generowanie wyników w czasie rzeczywistym.
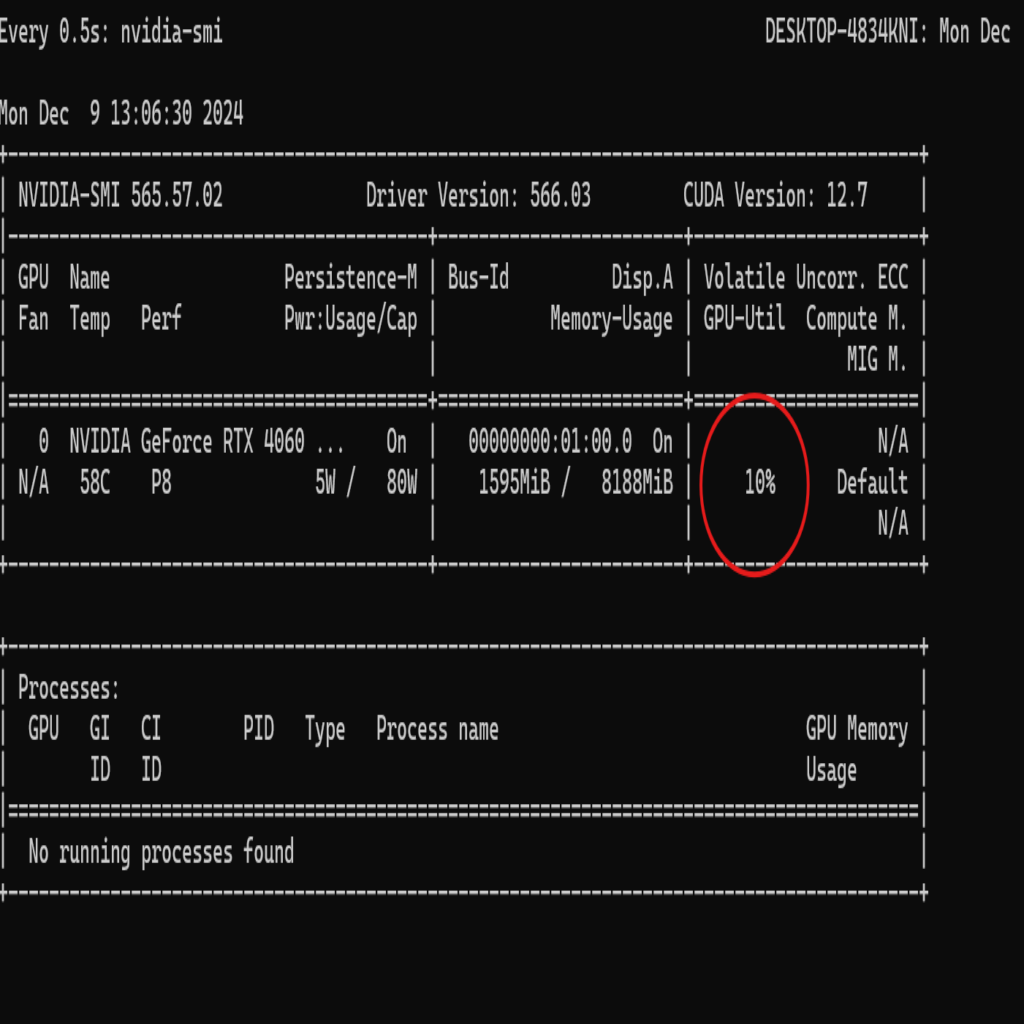
Możesz monitorować użycie karty graficznej poprzez komendę
watch -n 0.5 nvidia-smi