
Outsourcing IT dla małych i średnich firm: stabilność, bezpieczeństwo danych i kontrola kosztów w jednej usłudze. Sprawdź korzyści i umów konsultację.
Ile kosztuje wdrożenie systemu ITSM w Polsce: Etapy, Koszt, ROI, Utrzymanie
Kompletny przewodnik po wdrożeniu ITSM w Polsce: szczegółowy koszt, etapy wdrożenia, realny ROI (150-300%), harmonogram 4-6 miesięcy. Dla firm w Warszawie i całej Polski. Bezpłatny audyt.
Kalkulator Outsourcingu IT
Sprawdź, ile naprawdę kosztuje outsourcing IT. Nasz kalkulator w minutę oszacuje miesięczny koszt usług IT dla Twojej firmy. Porównaj oferty i zaoszczędź. Darmowa, niezobowiązująca wycena.

Kalkulator Outsourcingu IT
Oblicz koszt kompleksowego outsourcingu IT z monitoringiem MOC/SOC 24/7, backupem 3-2-1, ochroną BitDefender oraz profesjonalnym Help Desk i Service Desk. Oszczędź do 40% w porównaniu z utrzymaniem własnego zespołu.
9 strategicznych powodów, dla których własny dział IT to balast organizacyjny
Własny dział IT generuje ukryte koszty, luki w bezpieczeństwie i problemy z rekrutacją. Poznaj 9 strategicznych powodów, dla których to balast. Dowiedz się, jak outsourcing IT od 99net.pl zapewnia przewidywalność, skalowalność i strategiczną przewagę dla polskich firm
Najpoważniejsze błędy podczas transformacji cyfrowej i wdrożenia systemu ITSM
Idealny konsultant OPS to strategiczny partner transformacji cyfrowej. Poznaj 7 błędów transformacji cyfrowej i dowiedz się, jak profesjonalny konsultant OPS z 99net.pl pomaga polskim firmom uniknąć kosztownych błędów, zoptymalizować koszty IT i przeprowadzić bezpieczną transformację. Umów bezpłatny audyt.
Od Reaktywności do Autonomii: 5 Poziomów Dojrzałości IT 5.0
Kompleksowy przewodnik po transformacji IT 5.0: od systemów reaktywnych po organizacje autonomiczne. Dla firm w Warszawie i Polsce – analiza 5 poziomów dojrzałości, case studies, dane rynkowe i mapa drogowa.
Backup 3-2-1: Złota Zasada Ochrony Danych
Backup 3-2-1 to uznana na całym świecie najlepsza praktyka w dziedzinie ochrony danych. Jej geniusz tkwi w prostocie i skuteczności – jest łatwa do zapamiętania, a jednocześnie tworzy wielowarstwowy system zabezpieczeń, który minimalizuje ryzyko utraty danych do niemal zera.

Outsourcing IT w Polsce – Kompleksowe Rozwiązania dla Firm
Czy wiesz, że 78% polskich firm decyduje się na outsourcing IT, aby obniżyć koszty i zwiększyć efektywność? W erze cyfrowej transformacji, profesjonalne zarządzanie IT to nie luksus, ale konieczność biznesowa. Dowiedz się, dlaczego outsourcing IT w Polsce to najlepsza inwestycja dla Twojej firmy.


Experience Economy Metrics – Pomiar wartości doświadczenia, a nie tylko usługi

AI-Native Metrics: Metryki generowane i interpretowane przez AI
Odkryj, jak sztuczna inteligencja redefiniuje pomiary IT. AI-Native Metrics to dynamiczne, samouczące się wskaźniki, które przewidują problemy, generują insighty i optymalizują infrastrukturę. Zarezerwuj bezpłatną konsultację z ekspertami AI!

Od zera do IT managera: jak znaleźć pierwszą pracę w IT i zbudować karierę
Poznaj kompletny przewodnik jak rozpocząć karierę w IT bez doświadczenia. Dowiedz się jak znaleźć pierwszą pracę w branży technologicznej i awansować od stanowiska juniorskiego do IT managera. Praktyczne porady, ścieżka kariery krok po kroku oraz kluczowe umiejętności potrzebne do sukcesu w informatyce.

Od chaosu do skuteczności: Onboarding, który naprawdę działa (nie tylko w branży IT)
Przez 22 lata kariery nie spotkałem dobrego onboardingu. Przedstawiam praktyczny proces WWP z cotygodniowymi przeglądami. Dowiedz się jak wdrożyć skuteczny onboarding w każdej branży – nie tylko IT.

Major Incident Management: Strategiczne zarządzanie krytycznymi awariami


Piramida Wartości IT 5.0: Dlaczego Inwestycja w Ludzi jest Fundamentem Sukcesu Technologicznego
Ludzie, procesy, narzędzia, usługi, klienci – odkryj model piramidy wartości w IT 5.0. Dlaczego zaawansowane technologie zawodzą bez solidnych fundamentów? Poznaj case study i dowiedz się, gdzie powinna skupiać się twoja strategia.

Służyć i przewodzić: Kim będzie nowoczesny manager IT?
W erze cyfrowej transformacji AI, chmury obliczeniowej i zwinnych metodologii, nowoczesny manager IT przestał być jedynie zarządcą technologii, a stał się architektem wartości biznesowej. To jedna z najbardziej dynamicznie ewoluujących ról w nowoczesnej organizacji.

Jak przygotować budżet IT krok po kroku – CAPEX, OPEX, MPK, TCO




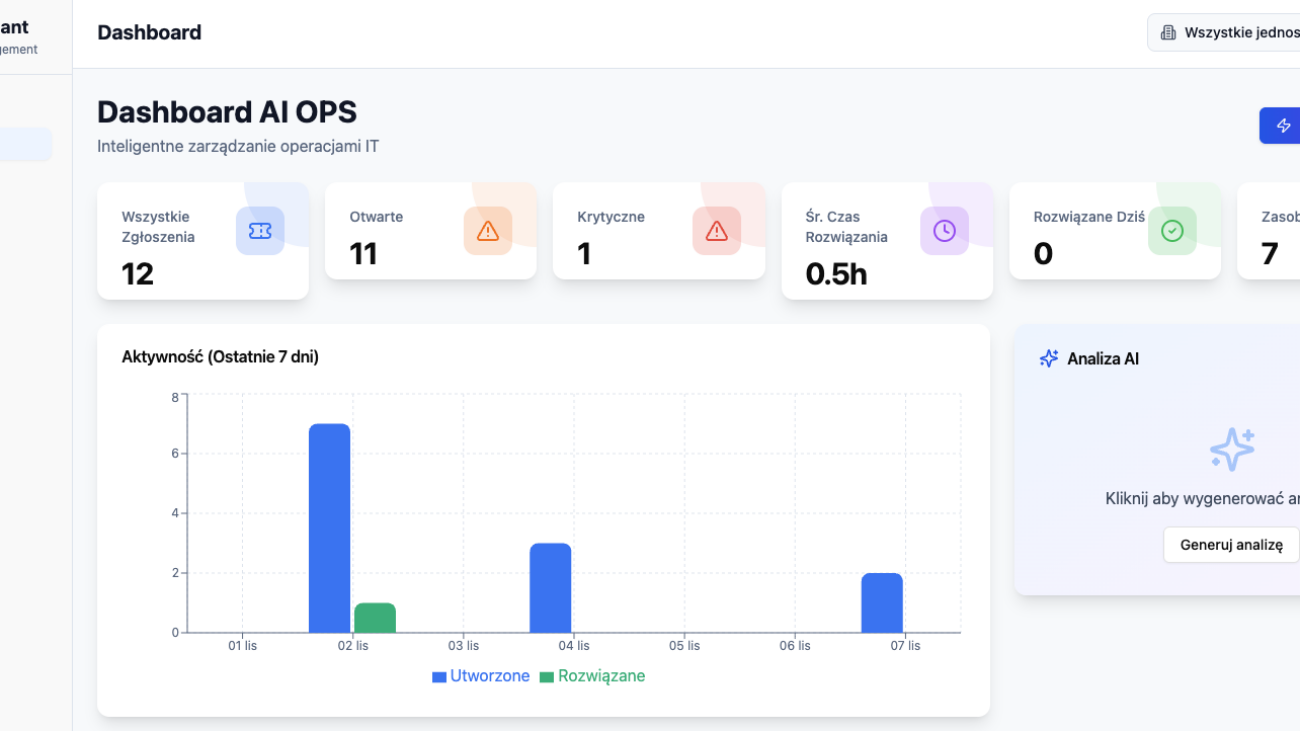
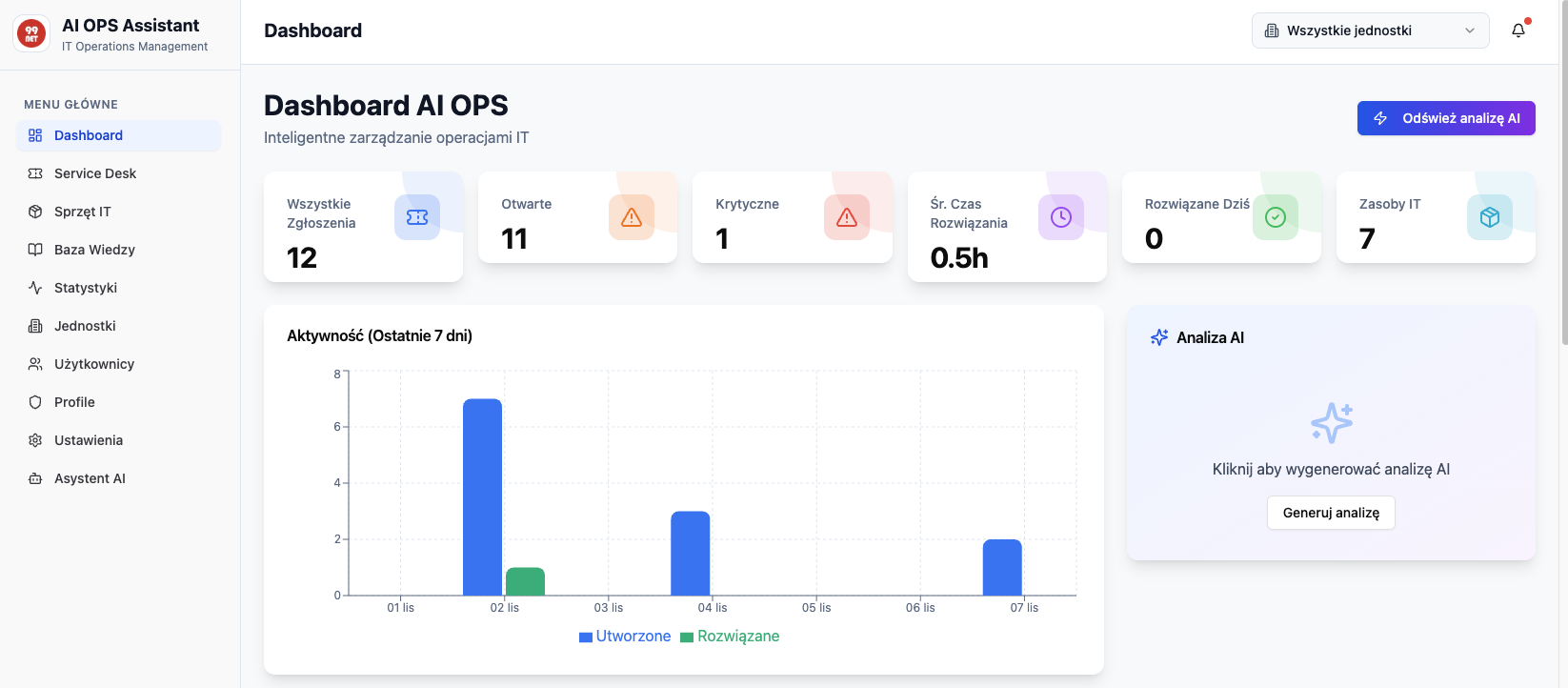
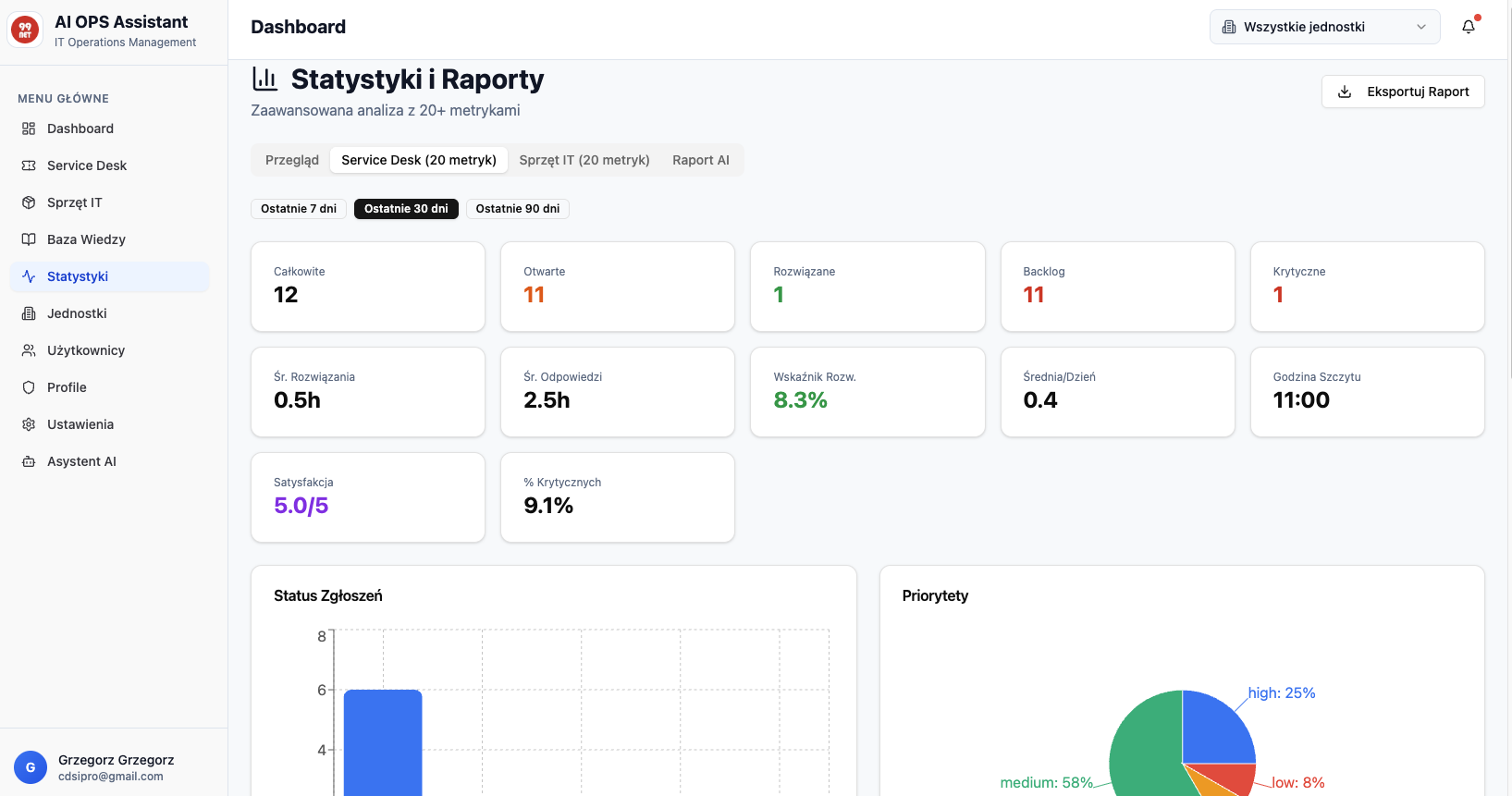
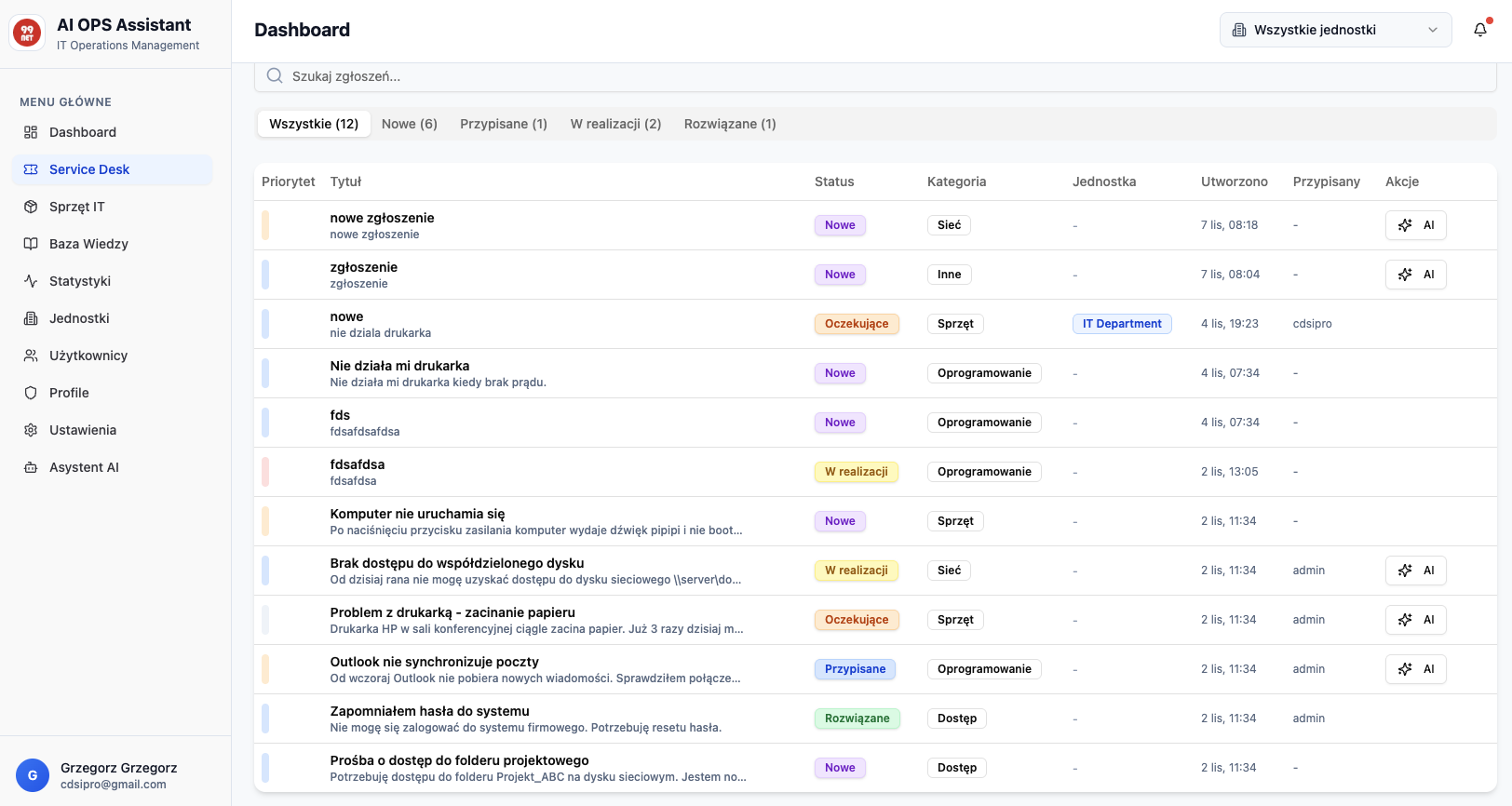
Model Wielowarstwowego Service Desk: Charakterystyka Linii Biznesowych


Palantir: Demistyfikacja „systemu wszystkowiedzącego”. Jak oprogramowanie kształtuje współczesną geopolitykę i biznes?
Palantir: System Wszystkowiedzący? Zastosowania, Kontrowersje, Przyszłość | Analiza
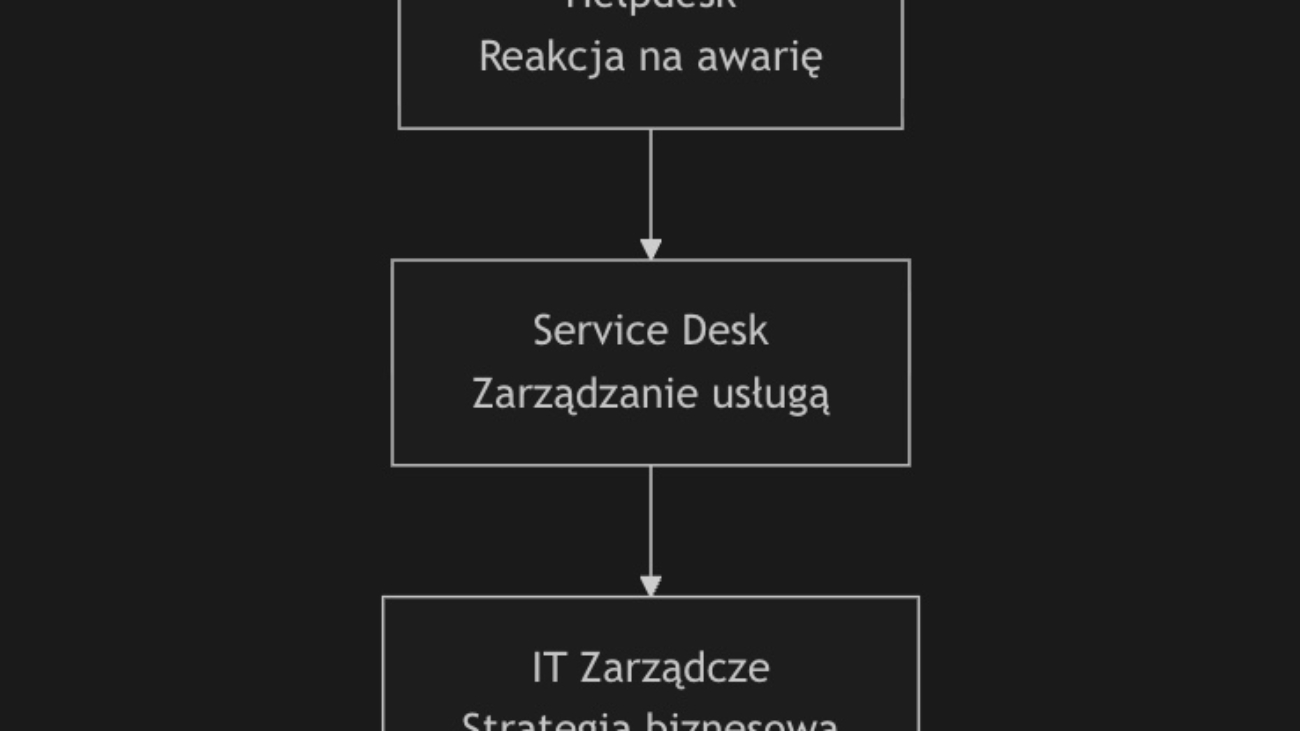
Helpdesk, Service Desk a IT Zarządcze: Ewolucja Wsparcia IT od Reakcji do Strategii
Czy Twój dział IT wciąż tylko „gaszi pożary”, a jego rolę postrzega się jako centrum kosztów? Poznaj trzy poziomy dojrzałości wsparcia technologicznego: od reaktywnego Helpdesku, przez zorientowany na usługi Service Desk, aż po strategiczne IT Zarządcze. Dowiedz się, jak przekształcić IT z kosztu w siłę napędową biznesu i strategicznego partnera w osiąganiu celów organizacji.
IT Manager as a Service: Innowacyjne Podejście do Zarządzania IT Twojej Firmy
IT Manager as a Service dla Twojej firmy. Zobacz, jak oszczędzić do 30% kosztów IT i zyskać strategicznego partnera technologicznego. Elastyczny abonament zamiast etatu.
Program HARPA – Nowa Era Bezpieczeństwa Zarządzania Informacją
HARPA – rewolucyjne cyberbezpieczeństwo dla firm w Polsce. 5 filarów: Hybrid Threat Intelligence, Automated Response, Real-time Risk Assessment, Predictive Analytics, Adaptive Architecture. Wdrożenie przez 99net.pl. Bezpieczeństwo IT, ochrona danych, SOC 24/7.

Audyt Jakości Pracy IT – Innowacyjna Usługa dla Twojej Firmy na Polskim Rynku
Nawet 30% zasobów IT jest marnowanych przez nieefektywne procesy. Nasz audyt jakości pracy IT identyfikuje problemy, proponuje rozwiązania i pokazuje, jak zmniejszyć koszty nawet o 40%. Działamy w oparciu o dane, nie domysły!
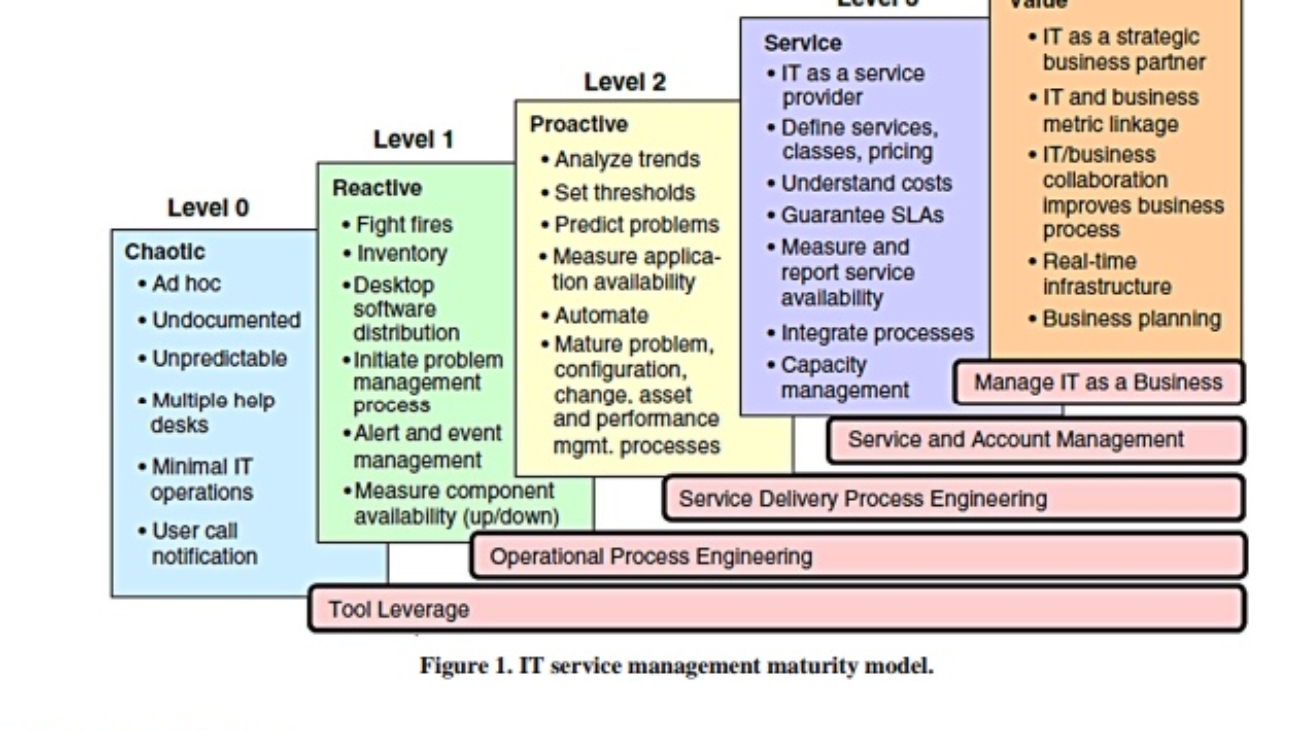
Budowanie dojrzałości IT: Kluczowa rola Service Desk w oparciu o ITIL i ITSM
Poznaj kluczowe elementy budowania dojrzałości IT w oparciu o ITIL i ITSM. Dowiedz się, jak nowoczesny Service Desk wpływa na efektywność zarządzania usługami IT, poprawę satysfakcji klientów i redukcję kosztów. Sprawdź case study i praktyczne wskazówki.

Organizacje „Ameby” – czyli firmy, które nie rozumieją strategicznej roli IT
Organizacje 'Ameby’ to firmy, które nie rozumieją strategicznej roli IT, traktując je jako koszt, a nie inwestycję. Dowiedz się, jak przekształcić 'Amebę’ w nowoczesną, cyfrowo dojrzałą organizację.
Podejście do Zarządzania IT: Reaktywność, Prewencja, Predyktywność i Preskrypcyjność
W dynamicznie zmieniającym się świecie technologii informatycznych (IT)
skuteczne zarządzanie infrastrukturą IT i procesami organizacyjnymi wymaga przyjęcia odpowiedniego podejścia. Współczesne firmy coraz częściej przechodzą od modelu reaktywnego do bardziej zaawansowanych strategii, takich jak prewencja, predyktywność i preskrypcyjność. Każde z tych podejść ma swoje zalety i zastosowanie, które można dostosować do specyfiki danej organizacji.

Reaktywność: Pierwszy krok w zarządzaniu IT
Reaktywność to podejście polegające na reagowaniu na problemy dopiero w momencie, gdy już się pojawią. W modelu reaktywnym administratorzy IT podejmują działania naprawcze w odpowiedzi na zgłoszenia użytkowników lub wykryte awarie.
Zalety reaktywności:
- Proste wdrożenie – wymaga mniej zaawansowanych narzędzi i procesów.
- Odpowiednie w sytuacjach kryzysowych, gdy szybka reakcja jest kluczowa.
Wady reaktywności:
- Brak proaktywnego podejścia zwiększa ryzyko wystąpienia poważnych awarii.
- Wyższe koszty związane z przestojami i nieplanowanymi naprawami.
- Zwiększone obciążenie działu IT.
Przykład w praktyce:
Firma korzystająca z reaktywnego podejścia czeka na zgłoszenia użytkowników dotyczące problemów, takich jak niedostępność serwera czy awarie sprzętu, zanim podejmie działania.
Prewencja: Zarządzanie przez zapobieganie
Prewencja to proaktywne podejście, które polega na identyfikowaniu i eliminowaniu potencjalnych problemów, zanim one wystąpią. Organizacje wdrażają procesy i narzędzia, które minimalizują ryzyko awarii i zakłóceń.
Zalety prewencji:
- Redukcja liczby incydentów IT dzięki wcześniejszemu wykrywaniu problemów.
- Poprawa niezawodności i ciągłości działania systemów.
- Obniżenie kosztów związanych z przestojami.
Wady prewencji:
- Wyższe koszty początkowe związane z wdrożeniem narzędzi i procesów monitorowania.
- Wymaga odpowiedniego planowania i zaangażowania zasobów.
Przykład w praktyce:
Firma korzystająca z prewencji wdraża system monitorowania serwerów, który identyfikuje zużycie zasobów i ostrzega administratorów przed potencjalnym przeciążeniem.
Predyktywność: Prognozowanie przyszłości na podstawie danych
Predyktywność to podejście wykorzystujące analizę danych i modele predykcyjne do prognozowania przyszłych zdarzeń. Dzięki zastosowaniu sztucznej inteligencji i uczenia maszynowego możliwe jest przewidywanie awarii, trendów w obciążeniu systemów czy zapotrzebowania na zasoby.
Zalety predyktywności:
- Większa dokładność w identyfikowaniu potencjalnych problemów.
- Optymalizacja kosztów dzięki lepszemu planowaniu zasobów.
- Poprawa wydajności systemów i użytkowników.
Wady predyktywności:
- Wymaga zaawansowanych narzędzi analitycznych i specjalistycznej wiedzy.
- Wyższe koszty implementacji.
Przykład w praktyce:
Firma wykorzystująca predyktywność analizuje dane historyczne z systemów IT, aby przewidzieć moment, w którym dyski twarde w serwerach osiągną limit swojej wydajności, i planuje ich wymianę z wyprzedzeniem.
Preskrypcyjność: Automatyzacja decyzji i działań
Preskrypcyjność to najbardziej zaawansowane podejście, które nie tylko przewiduje problemy, ale również sugeruje lub automatycznie wdraża działania naprawcze. Opiera się na zaawansowanej analityce i mechanizmach sztucznej inteligencji, aby podejmować decyzje w czasie rzeczywistym.
Zalety preskrypcyjności:
- Automatyzacja procesów zmniejsza obciążenie działu IT.
- Szybka reakcja na sytuacje kryzysowe.
- Optymalizacja zarządzania zasobami.
Wady preskrypcyjności:
- Wysokie wymagania technologiczne i koszt wdrożenia.
- Potrzeba zaawansowanego modelu zarządzania zmianami w organizacji.
Przykład w praktyce:
Firma wdraża system, który automatycznie przełącza obciążenie na zapasowe serwery w przypadku awarii głównego systemu, jednocześnie wysyłając zgłoszenie do działu IT i generując raport o problemie.
Porównanie podejść
| Podejście | Zastosowanie | Korzyści | Wyzwania |
|---|---|---|---|
| Reaktywność | Działania naprawcze | Szybka reakcja na incydenty | Wyższe koszty i ryzyko przestojów |
| Prewencja | Zapobieganie problemom | Redukcja liczby awarii | Wyższe koszty początkowe |
| Predyktywność | Prognozowanie przyszłych zdarzeń | Optymalizacja planowania zasobów | Wymaga zaawansowanej analizy danych |
| Preskrypcyjność | Automatyzacja decyzji | Maksymalna efektywność i szybkie działania | Wysokie koszty wdrożenia i zarządzania |
Jak wdrożyć te podejścia w organizacji?
- Ocena potrzeb organizacji: Przeanalizuj aktualne podejście i potrzeby w zakresie zarządzania IT.
- Dobór odpowiednich narzędzi: Wybierz oprogramowanie, które wspiera monitorowanie, analizę danych i automatyzację.
- Szkolenia zespołu: Zapewnij szkolenia dla zespołów IT, aby efektywnie wdrożyć nowe podejścia.
- Ewolucja krok po kroku: Stopniowo przechodź od reaktywności do bardziej zaawansowanych strategii.
Podsumowanie
Zarządzanie IT wymaga dynamicznego podejścia, które pozwala na dostosowanie strategii do specyfiki organizacji. Przejście od reaktywności do prewencji, predyktywności i preskrypcyjności może znacząco poprawić wydajność i niezawodność systemów IT. Wybór odpowiedniego modelu zależy od poziomu zaawansowania organizacji, dostępnych zasobów i celów biznesowych.
Dzięki nowoczesnym technologiom i narzędziom każda firma może skutecznie wdrażać te podejścia, zwiększając swoją konkurencyjność i stabilność operacyjną.